
What Is Photonic Computing and Will It Replace GPUs? A Technical and Investment Assessment
Not yet replacing GPUs. Photonic interconnect has arrived and is scaling fast. Photonic tensor cores are 24 to 36 months behind on a good trajectory.


Photonic Neural Networks in 2026: Can Light Replace Electrons for High-Performance Compute?
Light as the New Medium of Compute
Photonic computing has crossed a decisive threshold between April 2025 and Q1 2026: two peer-reviewed Nature papers (Lightmatter and Lightelligence, 9 April 2025) demonstrated integrated photonic AI accelerators running real workloads (ResNet, BERT, reinforcement-learning Atari) at 7–10-bit effective precision, while Marvell’s December 2025 acquisition of Celestial AI for up to $5.5 B validated optical interconnect as the dominant near-term commercialization path. The field is no longer a laboratory curiosity; it is a contested semiconductor adjacency with >$2 B of 2024–2025 venture funding, three Tier-1 M&A transactions, and explicit placement on Gartner’s 2025 Hype Cycle for Data Center Infrastructure.
Yet the locus of commercial viability has shifted decisively from “photonic compute” to “photonic I/O and scale-up fabrics,” with compute-in-light products (Q.ANT NPU 2, Lightmatter Envise) trailing by roughly 24–36 months. This report assesses the five physical-layer components that determine whether photonic neural networks will graduate from niche HPC accelerators to mainstream AI infrastructure during the 2026–2030 window.
The architecture stack sits on five contested components
Photonic neural networks (whether coherent Mach-Zehnder meshes, incoherent WDM broadcast-and-weight banks, or free-space diffractive networks) reduce to five device families that collectively determine throughput, precision, energy efficiency, and manufacturability. Micro-ring resonators (MRRs) encode analog weights via wavelength selective attenuation.
Frequency microcombs supply the parallel WDM channels that let a single photonic tensor core operate across tens-to-hundreds of wavelengths. Programmable metasurfaces extend the same weighting function to free-space and multi-mode on-chip diffractive architectures, with phase-change materials adding non volatility. VCSELs act both as light sources for datacenter interconnects and as compact nonlinear nodes for neuromorphic/reservoir computing. Variable optical attenuators and photodiodes close the loop: the former imprint singular-value weights on SVD decomposed matrices, the latter perform the analog summation step of each MAC and ultimately dictate the achievable ENOB.
Each device family is on a distinct maturity curve, and the fastest-moving commercial money is flowing to the components most directly tied to AI-cluster interconnect (high speed photodiodes, VCSELs, microcombs as multi-wavelength sources, and MRR-based modulators within CPO transceivers), not to compute. Compute-grade demonstrations remain at 128×128 photonic tensor cores per die and <80 W TDP (Lightmatter’s Ahmed et al., Nature 640, 368–374, April 2025); impressive, but still below the 400 TOPS design targets cited in the same paper.
Micro-ring resonators: compact, scalable, but thermal drift is a cliff
MRRs remain the densest demonstrated synaptic element per MAC and the core building block of broadcast-and-weight architectures traceable to Tait/Prucnal at Princeton (2014). Three 2025 results redraw the state of the art. Meng et al., Light: Science & Applications 14, 27 (2025) exploited time–wavelength microwave multi-domain multiplexing in a single MRR to reach 34.04 TOPS/mm², roughly 10× the prior MZI/MRR/PCM density record at 30.67 GBaud with 96.41% MNIST accuracy. Lightmatter’s Ahmed et al. (Nature 2025) vertically integrated four 128×128 photonic tensor cores with two 12 nm digital control dies, delivering 65.5 TOPS in ABFP16 at 78 W electrical + 1.6 W optical and running BERT and DeepMind-class RL out-of the-box at near-electronic accuracy. Hua et al./Lightelligence (Nature 640, 361) shipped PACE, an over-16,000-component photonic arithmetic engine with 5 ns minimum latency and 7.61 average ENOB at 1 GHz, outperforming GPUs on Ising/max-cut optimization by ~500×. On precision, Liu et al. (OFC 2025, W3D.2) pushed calibration-free MRR programming beyond 9-bit precision on a photonic eigensolver, extending the canonical Zhang/Queen’s 2022 9-bit dither benchmark.
The engineering wall is thermal. Silicon’s thermo-optic coefficient of ~1.8×10⁻⁴ K⁻¹ translates to 80–100 pm/K resonance shifts, and a 2024 arXiv simulation (2401.08180) showed a two-layer MNIST PNN’s accuracy collapsing from 99.0% to 67.0% under realistic ambient thermal fluctuations, with CIFAR crashing from 83.6% to 9.15%. The baseline thermo-optic heater budget is ~28 mW per FSR, implying kilowatts of tuning power across a 512-wavelength PNN, comparable to GPU TDP and an obvious show stopper. Mitigations are proliferating: Xu et al. (Adv. Opt. Mater. 2402706, 2025) show 44.7% heater-power reduction via power-aware pruning; TiO₂-cladded TFLN MRRs (Ling et al., Univ. Rochester) deliver first-order athermal operation with <0.33 nm drift across a 60 K window; and photochromic cladding now corrects fabrication induced resonance offsets without persistent heater power. Thin-film lithium-niobate MRRs (Wang et al., Opt. Lett. 50, 3094, May 2025; Su et al., ACS Photonics 12, 2062, 2025) deliver nanosecond tuning via electro-optic rather than thermo-optic effects; the decisive architectural bet underlying Q.ANT’s commercial roadmap
Commercial positioning converges on a bifurcated map. Lightmatter ($850 M total raised, $4.4 B valuation after October 2024 Series D, 315 employees as of Q1 2026) uses an MRR/MZI hybrid and has pivoted its near-term go-to-market to the Passage interposer family (M1000: 114 Tbps across 4,000 mm², 256 optical fibers, announced April 2025; L200 3D CPO at 32–64+ Tbps aligned to XPU/switch silicon). Lighttelligence and Q.ANT (€62 M Series A July 2025, NPU 2 shipping H1 2026 at 150 W and 8 GOPS on a 2 GHz TFLN die) remain the two pure-play compute vendors with productized silicon. Salience Labs ($30 M April 2025 Series A) pivoted from PCM-MRR compute to silicon-photonic optical circuit switches, telegraphing the difficulty of monetizing MRR-based compute directly. Luminous Computing effectively exited the category after a May 2023 photonics team layoff. Foundry ecosystem maturation is decisive: imec’s iSiPP300 was licensed to UMC on 8 December 2025, with risk production scheduled for 2026/2027; AIM Photonics, GlobalFoundries 45CLO, and TSMC COUPE complete the 200/300 mm supply chain.
Outlook (2026–2030): MRRs will scale to 512×512 tensor cores in existing foundry flows, but precision will plateau at 8–10 bits absent digital re-correction or architectural innovations like ASTRA’s homodyne accumulation (ACM TECS 2026). Yole forecasts the first optical-processor shipments in 2027–2028 and ~1 M units by 2034. The dominant monetization pathway over the next 36 months is MRR-as modulator within CPO transceivers, not MRR-as-synapse within tensor cores; photonic compute economics still require proof of >3–5× energy advantage at production scale to dislodge an NVIDIA/AMD/Google supply chain shipping B200 and TPU v7 Ironwood in 2025 2026.
Frequency microcombs: the WDM multiplier that finally works on-chip
Microcombs collapse hundreds of independently tunable DFB lasers into a single nonlinear microresonator, and 2025 was the year on-chip integration crossed system-level thresholds. Pappas et al. (APL Photonics 10, 110805, November 2025) built a 262 TOPS hyperdimensional photonic AI accelerator around a 16×16 AWGR driven by an integrated Si₃N₄ microcomb, hitting 92.14% on MNIST and Cohen’s κ = 0.87 on DDoS detection at 32 GBaud. Wang/Liao/Hu et al. (eLight, 2025) integrated a turnkey DFB-pumped soliton microcomb at 100 GHz FSR with MRR+MZI arrays to deliver 2.45 TOPS/mm² across FCNN/CNN/PGRNN workloads. Song/Hu/Lončar (Light: Science & Applications 14, 270, 2025) set the line-count record at 2,589 comb lines across a 75.9 THz span with 29.308 GHz spacing on TFLN.
Gil-Molina/Lipson/Gaeta (Nature Photonics, October 2025) delivered 158 mW on-chip power with 27 usable lines from a multimode gain chip self-injection-locked to a SiN normal-GVD ring; the first electrically pumped high-power microcomb using a genuinely low-coherence pump. Niu/Liu/Dong (arXiv 2505.15001, May 2025) demonstrated 43.9% steady-state pump-to-soliton conversion efficiency via an integrated LNOI pulse pump driving a SiN microresonator; breaking through the classical 1–15% CW-DKS efficiency ceiling that long capped microcomb power budgets.
The persistent engineering constraints are efficiency, thermal stability of anomalous-GVD solitons, and pump integration. Dark-pulse combs on AlGaAsOI address efficiency (routinely 30–50%) and are inherently thermally self-stabilizing. Bai/Chang/Bowers (Nature Communications 14, 66, 2023) showed the reference photonic processor running at 1.04 TOPS/mm² with no feedback electronics. RIN has now reached −160 dBc/Hz, approaching quantum-limited for DWDM coherent links.
The commercial field is narrow but real. EnLightra (EPFL spinout) raised $15M cumulatively through December 2025 (Y Combinator W22, Runa Capital, Pegasus, Protocol Labs; co-founder Maxim Karpov named MIT TR35 2025) and is shipping 8- and 16-channel microcomb laser modules aligned to the CW-WDM MSA, with pilot production slated for 2027. Pilot Photonics (DCU spinout) launched a 16-channel 200 GHz O-band CW-WDM MSA product in March 2025 using its ExCELS™ hybrid gain-switched-comb + DFB-array architecture. Microcomb Pty (Swinburne spinout) and OEwaves (crystalline WGM specialist, Pasadena) round out the roster.
Outlook: Microcombs will displace DFB arrays specifically in the >16 λ regime demanded by 200G-SerDes-era CPO, with dark-pulse combs on AlGaAsOI and SiN+InP heterogeneous integration as the leading platforms and TFLN variants adding EO tunability on a single die. The gating specifications are 0–5 dBm per line with <−145 dB/Hz RIN and yield parity with DFB arrays; targets plausibly hit by 2028–2030.
Metasurfaces: the free-space wildcard, still largely non reconfigurable at scale
Programmable metasurfaces occupy the most fragmented corner of the photonic-AI stack. The dominant 2024–2025 literature converges on three material systems. Phase-change chalcogenides (GST, GSST, Sb₂S₃, and Sb₂Se₃) — provide non-volatile, nanosecond switchable refractive-index contrast and 4- to 6-bit analog weight storage; the Wu et al. (2021, Nature Communications) phase-change metasurface mode converter (PMMC) remains the canonical reference, delivering 6-bit precision on a 2×2 kernel, and has been extended in 2024–2025 by groups at Fudan (GST-based heterogeneously integrated THz metasurfaces, reconfigurable dual-functional switching), Oxford/Münster (Bhaskaran, Pernice), and Chinese universities using Sb₂Se₃ direct-laser-write schemes (Scientific Reports 2025, 19638). A seven-bit non-volatile electrically programmable N-doped GST photonic device (ACS Photonics 2023, extensively cited through 2025) reaches ~17 fJ/MAC with 4-bit-equivalent weights. Gao et al. (Advanced Materials e08029, 2025) reviews the broader integrated neuromorphic-photonic landscape and positions metasurfaces as a key reconfigurability pathway.
Electro-optic tunability comes from ITO-gated meta-atoms, liquid-crystal-on-silicon, and MEMS-tunable dielectric metasurfaces. A comprehensive arXiv roadmap (2505.11659, May 2025, “Programmable metasurfaces for future photonic artificial intelligence”) synthesizes the state of the art: subwavelength LC meta-atoms now approach 1 µm pixel pitch (Aso et al., JSID 2024; Isomae et al., JSID 2019) with ferroelectric drive, and AC-biased programmable metasurfaces can simultaneously encode multiple outputs at harmonic frequencies; a rare multiplexing dimension absent in MRR or MZI architectures. On the diffractive-neural-network side, UCLA’s Ozcan group continues to produce the reference benchmarks: D²NNs with wavelength and polarization multiplexing (Advanced Photonics 5, 016003), reconfigurable permutation operations (Ma et al., Laser & Photonics Reviews 2400238), and “Optical generative models” (Nature 644, 903, 2025).
The productization obstacles are brutal: PCM cycling endurance typically 10⁶–10⁸ switches (inadequate for frequent training updates), switching energies of ~nJ per meta-atom, amorphous-vs-crystalline optical loss asymmetry, and drift over days-to-weeks. CMOS compatible drivers and millions of individually-addressable meta-atoms remain an open integration challenge. Consequently, the commercial layer is concentrated in imaging and LiDAR, not AI compute: Metalenz (Samsung investment, shipping flat-optic imagers), Lumotive (beam-steering LiDAR, BMW partnership 2024–2025), NIL Technology, and Bodle Technologies (PCM displays, Oxford-lineage) are the revenue-generating players. Samsung and Meta Reality Labs carry out AR/VR-oriented metasurface R&D with little crossover to photonic neural networks.
Outlook: Metasurface based AI inference remains a 5–7-year horizon for production hardware; the material likely to win is Sb₂Se₃ for its low loss and multi-level programmability, with ITO or LC-based electro-optic meta-atoms supplying the reconfigurability that D²NNs require for practical deployment. Near-term, metasurfaces will appear first as fixed weight layers co packaged with CMOS imagers for edge inference (compact eternal diffractive chips, Communications Engineering 3, 64, 2024), not as general-purpose datacenter accelerators.
VCSELs: dual-role device at the interconnect–compute boundary
VCSELs occupy both roles in photonic AI (datacenter light sources and nonlinear neurons) and 2025 marked a substantial bandwidth inflection. Broadcom’s Wang/Murty et al. (MDPI Photonics 13(1):90, January 2026) demonstrated an 850 nm oxide-confined VCSEL at >35 GHz −3dB bandwidth with 200 Gb/s PAM-4 over 50 m OM4 and <−152 dB/Hz RIN, error-free over 9 hours. Coherent + Keysight (OFC 2025) ran a live 200 Gb/s/lane PAM-4 demo for 1.6T multimode transceivers.
Koyama’s Tokyo Tech group hit 45 GHz and 200 Gb/s PAM-4 at 90 fJ/bit on a 1060 nm coupled-cavity VCSEL with an intra-cavity metal aperture. VI Systems / Ledentsov reached intrinsic f₋₃dB,opt ≥42 GHz on small-aperture (2 µm) single-mode devices. Record polarization oscillation frequencies >200 GHz in spin-VCSELs (Lindemann et al., Nature 568, 212) remain the theoretical ceiling, but electrically driven birefringence control is not yet productizable.
On the neuromorphic side, Owen-Newns/Jaurigue/Robertson/Lüdge (Communications Physics 8, 110, March 2025) demonstrated a single-VCSEL photonic spiking neural network at 1300 nm with ~100 ps spikes and 512 virtual nodes, accurately predicting Mackey-Glass chaotic series with only 1,600 training points. Hejda et al. integrated a spiking VCSEL with a silicon-PIC MRR weight bank in the first WDM-compatible photonic-spiking system; directly unifying three of the five components in this report. A competing silicon-photonic reservoir computer (Wang et al., Nature Communications 15, December 2024) hit 200 TOPS at >60 GHz with two orders of magnitude higher energy efficiency than digital, raising the bar VCSEL-RC systems must clear to productize.
The industrial supply chain consolidated aggressively. NVIDIA’s March 2026 $4 B combined strategic investment in Lumentum and Coherent (split roughly evenly between equity and purchase commitments) locked in CPO + photonics supply for AI GPU clusters. Coherent, Lumentum, and Broadcom collectively dominate datacom VCSELs; Vertilite (China, FabX facility March 2025) and TRUMPF Photonic Components (InP >1300 nm mass production) diversify the base. IQE supplies 6-inch GaAs epi across the ecosystem. CPO transceivers (Broadcom Bailly 51.2 T, NVIDIA Quantum-X Q3450) consume ~5.4 W per 800G vs. ~15 W for 2×FR4 pluggables, which is the clearest near-term photonic energy-efficiency win, with >26% CAGR and CPO market exceeding $20 B by 2036 (IDTechEx)
Outlook: Volume 200 Gb/s/lane VCSELs ramp in 2026, 400 Gb/s/lane prototypes (Lumentum, OFC 2026) follow in 2028–2029, and single-mode 1310 nm long-wavelength VCSELs enter datacom by late 2026 2028. VCSEL-based neuromorphic computing remains research-grade; commercial adoption is 3–5 years away and faces stiff competition from silicon-photonic reservoir platforms.
Optical attenuators and photodiodes: the analog-precision bottleneck
The VOA-PD pair closes the photonic compute loop and ultimately sets the achievable ENOB. On the attenuator side, PIN-diode absorbers, thermo-optic MZI attenuators, MRR weight banks, and PCM-based 4-bit non-volatile weights all coexist; a 2025 MDPI Photonics paper reports polarization-insensitive silicon-photonic VOAs at 250×850 µm² with ≥18 dB attenuation at 3 V. Kincaid et al. (Communications Engineering, 2025) establishes that modulator nonlinearity (shared by MZI, MRM, and RAMZI attenuators) sets per-channel ENOB and must be jointly optimized with PD shot noise across WDM, SDM, and TDM PNN architectures.
Photodiode records accelerated sharply in 2025. IHP’s Ge-fin PD on Si reached 265 GHz with 0.3–0.45 A/W responsivity, co-integrated with >110 GHz GeSi EAMs on a 200/300 mm SOI platform (Nature Photonics 2021, extended in Scientific Reports 2025). Zou et al. (Nature Communications 16, 11058, 2025) reported a Ge/Si uni-multiplication-carrier APD at 105 GHz with gain 7, delivering 9 dB sensitivity improvement over PIN and supporting 284 Gb/s PAM-4. A lateral Si-Ge APD hit gain-bandwidth product of 7,564 GHz at 51 GHz with 0.85 A/W responsivity (Nature Communications 2026 / MDPI 2025). InP UTC-PDs micro-transfer-printed onto SiN delivered 155 GHz at 1 V bias with 0.3 A/W, enabling 300 GHz wireless at 160 Gb/s.
The MIT single-shot matrix-matrix photonic processor (Luan/Hamerly/Englund, Nature Communications 2026) achieved ~20 aJ/MAC at 96.4% image-classification accuracy via photoelectric multiplication at the PD, within striking distance of the 50 zJ/MAC standard quantum limit (Hamerly Phys. Rev. X 2019) and a demonstration that 0.66 photons/MAC suffices for 90% MNIST.
System-level ENOB, however, remains the binding constraint. PACE’s 7.61 ENOB and Lightmatter’s 7–10-bit effective precision both demand active calibration and adaptive block-floating-point schemes to survive the analog error budget. An arXiv 3D EPIC proposal (2508.03063) targets >12-bit ENOB at ~1 mW PD photocurrent and 100 MHz bandwidth, but only >8 bits at 300 MSPS; the DAC/ADC electronics, not the photonics, are now the bottleneck.
Outlook: PD bandwidth will reach 400+ GHz by 2028 to support 1.6 T coherent, while ENOB on production photonic accelerators will asymptote at 8–10 bits without fundamental architectural changes (e.g., bit-slicing, coherent homodyne accumulation). The decisive architectural question of coherent vs. incoherent, remains open, with Lightmatter’s 2025 design using both and industry convention leaning incoherent for inference and coherent for higher-precision linear algebra.
Where the commercialization curve actually sits
The overarching 2025–2026 story is not that “photonic computing arrived” — it is that photonic interconnect arrived and photonic compute is following at a lag. Three data points define the position on the maturity curve:
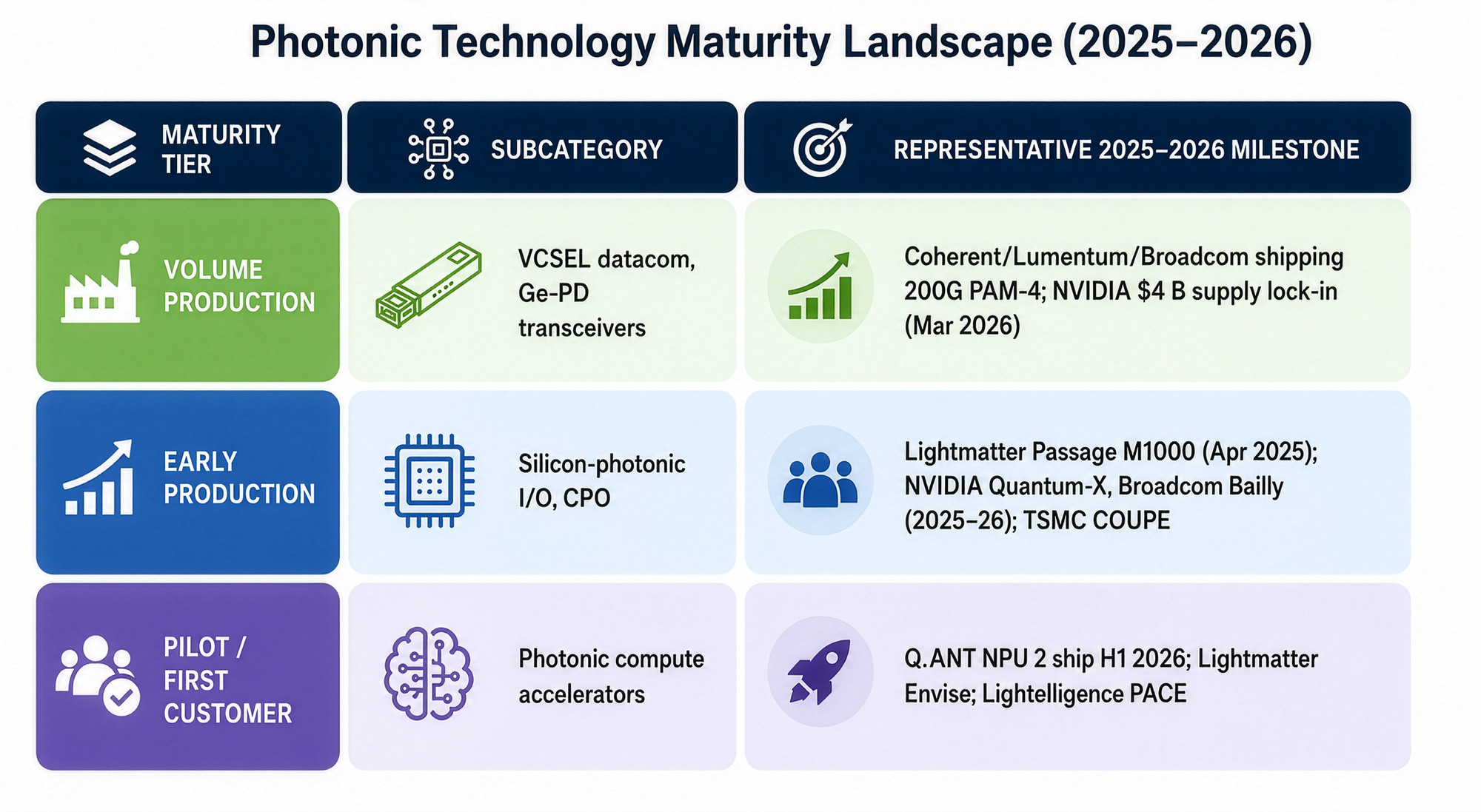
| Maturity Tier | Subcategory | Representative 2025–2026 Milestone |
|---|---|---|
| Volume production | VCSEL datacom, Ge-PD transceivers | Coherent, Lumentum, and Broadcom shipping 200G PAM-4; NVIDIA $4B supply lock-in (Mar 2026) |
| Early production | Silicon-photonic I/O, CPO | Lightmatter Passage M1000 (Apr 2025); NVIDIA Quantum-X; Broadcom Bailly (2025–2026); TSMC COUPE |
| Pilot / first customer | Photonic compute accelerators | Q.ANT NPU 2 ship H1 2026; Lightmatter Envise; Lightelligence PACE |
The energy-efficiency narrative is credible but unverified at scale. Q.ANT claims ~30× energy advantage vs. conventional CMOS for its TFLN NPU; Lightmatter’s April 2025 Nature paper achieved 65.5 TOPS at 78 W (~840 TOPS/W raw), comparable on compute but below an NVIDIA H100’s 2,000+ sparse TOPS at 700 W (~2,800 TOPS/W at INT8) once system overhead is included. Nature’s Communications Physics perspective (s42005 025-02300-0, 2025) argues that the Lightening-Transformer electro-photonic accelerator could produce >10× lower carbon emissions than an H100, but the comparison is inference only and uses aggressive assumptions. The honest read is that photonic compute achieves parity-to-modest-wins on raw TOPS/W today and wins decisively on interconnect energy (65–73% reduction per 800G, per Meta’s ECOC 2025 CPO paper). The datacenter AI optics market is expected to exceed $16 B in 2025 (>60% YoY growth); Dell’Oro forecasts AI back end switch spending >$100 B by 2030.
The M&A and funding signal is unambiguous. Marvell’s Celestial AI acquisition (announced December 2, 2025; closed February 2, 2026; up to $5.5 B cash-plus stock, Intel’s Lip-Bu Tan on the Celestial board prior to close) placed optical scale-up interconnect squarely inside a Tier-1 data-infrastructure incumbent. Lightmatter’s $400 M Series D at $4.4 B post-money (October 2024), Q.ANT’s €62 M Series A (July 2025), Salience Labs’ $30 M Series A (April 2025), and EnLightra’s $15 M cumulative total represent the supply-side capital that will underwrite 2026–2028 product generations. Academic leadership remains concentrated at MIT (Englund, Soljačić, Hamerly), Stanford (Fan, Miller, Vučković), Princeton/Queen’s (Prucnal, Shastri — 2025 Sloan Fellow), Oxford (Bhaskaran), EPFL (Kippenberg), Columbia (Bergman, Lipson), UCSB (Bowers, Blumenthal), Caltech (Marandi), and UCLA (Ozcan).
Five architectural trends will shape 2026–2030
First, photonic-electronic hybrids dominate: every production system co-packages CMOS control silicon (typically 12–16 nm) with photonic compute, because nonlinearities, DACs/ADCs, and memory remain more efficient in electrons. Second, coherent architectures are gaining share at the high-precision end (complex-valued matrices, coherent homodyne ENOB extension), while incoherent WDM broadcast-and-weight remains the density leader for inference. Third, TFLN is emerging as the preferred platform for compute where thermal crosstalk is intolerable, with Q.ANT, CHIPX (Shanghai Jiao Tong, 6-inch pilot line opened June 2025), Lightium, and HyperLight scaling manufacturing. Fourth, in-memory photonic computation using non-volatile PCMs bypasses the weight update bottleneck but is endurance-limited to ≤10⁸ cycles, making it suitable for inference rather than training. Fifth, diffractive/free-space architectures are being rehabilitated for edge AI and sensor-in-loop inference where sub-100λ form factors and compute-free propagation deliver unique energy wins.
The critical unresolved question is where photonic AI loses: training (still overwhelmingly electronic; Pai et al., Science 380, 398, 2023 remains the reference on-chip backprop demo, not yet at scale), memory access (DRAM integration unsolved), and nonlinearity (mostly electronic today, with native optical nonlinearity the Q.ANT NPU 2 bet). If analog precision ceilings remain at 8–10 bits, photonic compute will be relegated to inference for fixed-topology models; if bit-slicing, homodyne accumulation, or 12-bit ENOB techniques mature, photonic training becomes credible by 2028–2029.
Conclusion: the next three years will separate infrastructure from fantasy
Photonic neural networks have moved from promissory demonstrations to peer-reviewed Nature-class systems executing industry-standard workloads, but the field’s commercial center of gravity has shifted toward photonic I/O, interconnect, and scale-up fabrics, not fully photonic tensor cores. MRRs, VCSELs, and high-speed photodiodes are already revenue-generating inside AI-cluster optics; microcombs are 12–24 months out as multi wavelength source replacements for DFB arrays; TFLN compute engines (Q.ANT, Lightmatter) are pilot-deploying in 2025–2026; programmable metasurfaces for AI inference remain a 5–7-year project.
The near-term enterprise question is not “will photonics beat GPUs at compute?” but “will photonic interconnect allow GPUs to scale past the electrical bandwidth wall?”, and the December 2025 Marvell-Celestial and March 2026 NVIDIA-Lumentum-Coherent transactions answer that question emphatically in the affirmative.
The long-term question of photonic tensor cores displacing NVIDIA Blackwell and Rubin silicon remains open; on current trajectories it will be decided between 2027 and 2030 on three specific metrics, achievable ENOB, wall-plug efficiency at workload scale, and manufacturing yield on 300 mm photonic platforms. Strategic investors and hyperscaler infrastructure teams should treat photonic interconnect as a near-term capex line item and photonic compute as a high-variance, high-upside 2028+ bet whose winners will almost certainly emerge from the small cluster of firms (Lightmatter, Q.ANT, Lightelligence, Marvell-Celestial, and foundry partners imec/UMC, TSMC, GlobalFoundries) that already control the supply chain.






